RMI中对数据对象的序列化采用的是Java序列化。而目前主流的微服务框架却几乎没有用到Java序列化,SpringCloud用的是Json序列化,Dubbo虽然兼容了Java序列化,但默认使用的是Hessian序列化。
Java序列化的缺陷
1.无法跨语言
2.易被攻击
攻击者可以创建循环对象链,然后将序列化后的对象传输到程序中反序列化,这种情况会导致hashCode方法被调用次数呈次方爆发式增长, 从而引发栈溢出异常。例如下面这个案例就可以很好地说明。
Set root = new HashSet();
Set s1 = root;
Set s2 = new HashSet();
for (int i = 0; i < 100; i++) {
Set t1 = new HashSet();
Set t2 = new HashSet();
t1.add("foo"); //使t2不等于t1
s1.add(t1);
s1.add(t2);
s2.add(t1);
s2.add(t2);
s1 = t1;
s2 = t2;
}
解决
通过反序列化对象白名单来控制反序列化对象,可以重写resolveClass方法,并在该方法中校验对象名字。
使用 protobuf,JSON
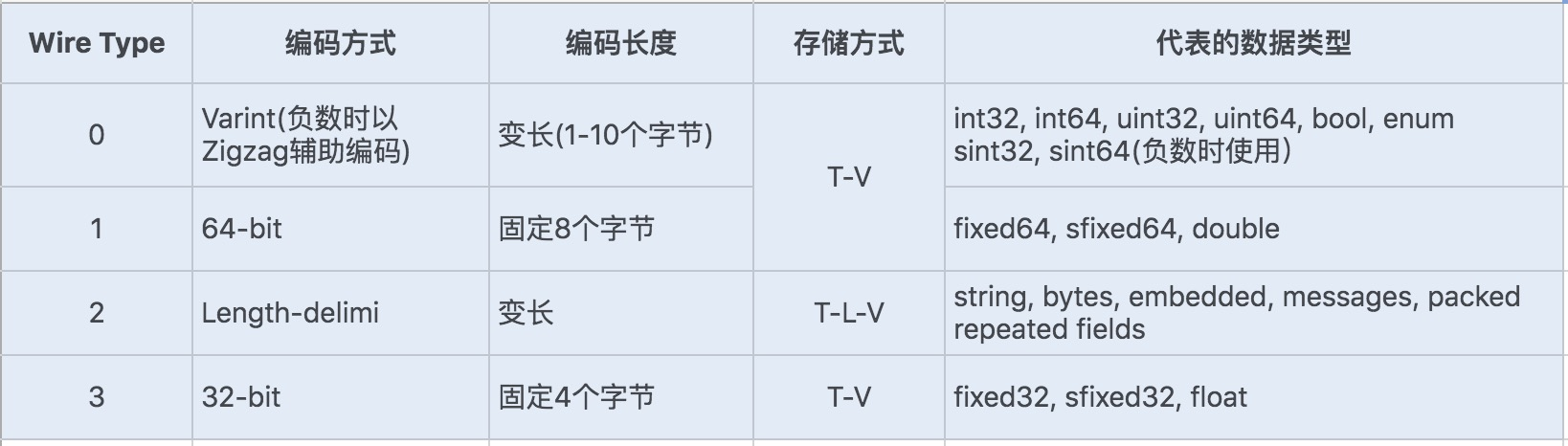
配图
protobuf 序列化

这是一个使用单例模式实现的类,如果我们将该类实现Java的Serializable接口,它还是单例吗?如果要你来写一个实现了Java的Serializable接口的单例,你会怎么写呢?
public class Singleton implements Serializable{
private final static Singleton singleInstance = new Singleton();
private Singleton(){}
public static Singleton getInstance(){
return singleInstance;
}}
导致这个问题的原因是序列化中的readObject会通过反射,调用没有参数的构造方法创建一个新的对象。
所以我们可以在被序列化类中重写readResolve方法。
private Object readResolve(){ return singleInstance; }